
През седмица, която беше добра за проследяване на дребни аномалии и грешки, се обръщаме към @joshuef за да обясни как се справяме с проблемите, дължащи се на сериализирането на съобщенията и стреса, който това създава върху мрежата. Нещо като обобщение…
Общ напредък
@davidrusu приключваше с проблем, при който Възрастните пропускаха анти-ентропийните проби преди разделянето, така че не винаги разполагаха с необходимата актуализирана информация за секциите.
Междувременно @bochaco работи върху списък с подобрения по отношение на как съхраняваме регистри (променливи данни - CRDT), включително промяна на някои вътрешни API заявки за съхранение за избягване на клониране на някои обекти, писане на отделни операции (вместо като един файл, който може да бъде презаписан от друг непълен CRDT), премахване на някои неизползвани типове грешки при съхранение и добавяне на повече контекстуална информация към други и разрешаване на съхранение на команди за редактиране на регистър за всички случаи (сега редът на постъпващите команди трябва да е по-малко важен, т.е. няма условие за състезание да има CreateRegister Cmd преди EditRegister, което имаме в основния клон).
И @chriso подобрява обработката на грешки в sn_node, включително вида съобщения за грешка, които се изпращат на клиента, за да улесни потребителите да видя какво става.
Сериализиране на съобщения
Видяхме от проучването на @southside, че мрежата изглежда е подложена на стрес при по-големи PUT данни. Неговите тестове с 2GB+ качвания хвърлиха светлина върху проблема там, който може да е част от причината… а може просто да е твърде много съобщения.
Това не означава, че изпращаме твърде много (въпреки че може да изпращаме и по-малко). Но изглежда, че напрежението при формирането на съобщения и скоростта, с която го правим, е твърде много.
Това е нещо, което сме виждали в heaptraces на използването на паметта на възела за известно време, но пътят напред за коригиране не беше напълно ясен.
Ние „сериализираме“ всяко съобщение в байтове и като се има предвид, че трябва да направим различен „MsgHeader“ за всеки възел, нямаше много начини да заобиколим това.
Но какво ще стане, ако не го направим?
Проучването на @southside отново извади въпроса на преден план и @joshuef, който беше раздразнен от количеството памет, използвано от сериализацията от известно време, реши да се опита да го подобри отново.
И този път се появи друга идея. Бяхме се опитали да премахнем необходимостта от Dst (дестинация, информация за това къде трябва да отиде съобщението) преди това… но не можем да направим това и да поддържаме нашите Anti-Entropy потоци живи. Така че това не беше възможно.
Но след няколко хакерски опита да актуализираме Dst Bytes в предварително сериализирано съобщение, за да избегнем повторната работа, осъзнахме, че набутваме квадратно колче в кръгла дупка. А именно, ограничението за предоставяне само на един байт от съобщение всъщност нямаше смисъл за нас.
Така че…
Така че след малко преструктуриране в qp2p, нашата мрежова обвивка, сега можем да изпратим три различни набора от Байтове през нашите връзки и от тях само един (нашият Dst) всъщност трябва да се промени, ако ние повторно изпращаме едно и също съобщение до различни възли!
Това означава, че вместо 7 пъти повече работа при изпращане на съобщение до Старейшините на секциите, сега е 1x - и ние използваме повторно Bytes за нашите MsgHeader и Payload! Трябва само да прекодираме Dst всеки път.
Спретнато.
Но чакайте… има още!
Това вече е прилично намаление на изчислителните разходи за изпращане на съобщение. Но има и друг ефект по отношение на паметта. Преди това по време на сериализирането на MsgHeader формирахме нашия един набор от Байтове чрез копиране на полезния товар (действителното съобщение, което изпращаме… така че ~1MB на парче), така че това е част от работата по разпределението на паметта и означава че всяко съобщение имаше свой собствен уникален набор от байтове, представляващи същия полезен товар. Така че изпращането на едно парче до четирима Възрастни ще има пет копия на това парче в паметта. ![]()
Но сега използваме евтино копие на Bytes (което е тип указател към основните данни…), така че не е необходимо дублиране на памет! Така че изпращането на едно парче до четирима възрастни сега трябва да се нуждае само от едно копие на данните ![]()
И на края
Ето как изглежда main. Тук виждаме три изпълнения на 250 клиентски теста (един PUT от 5MB и 250 клиента, които едновременно се опитват да получат тези данни), и след това 10 изпълнения на пълния стандартен набор от тестове sn_client.
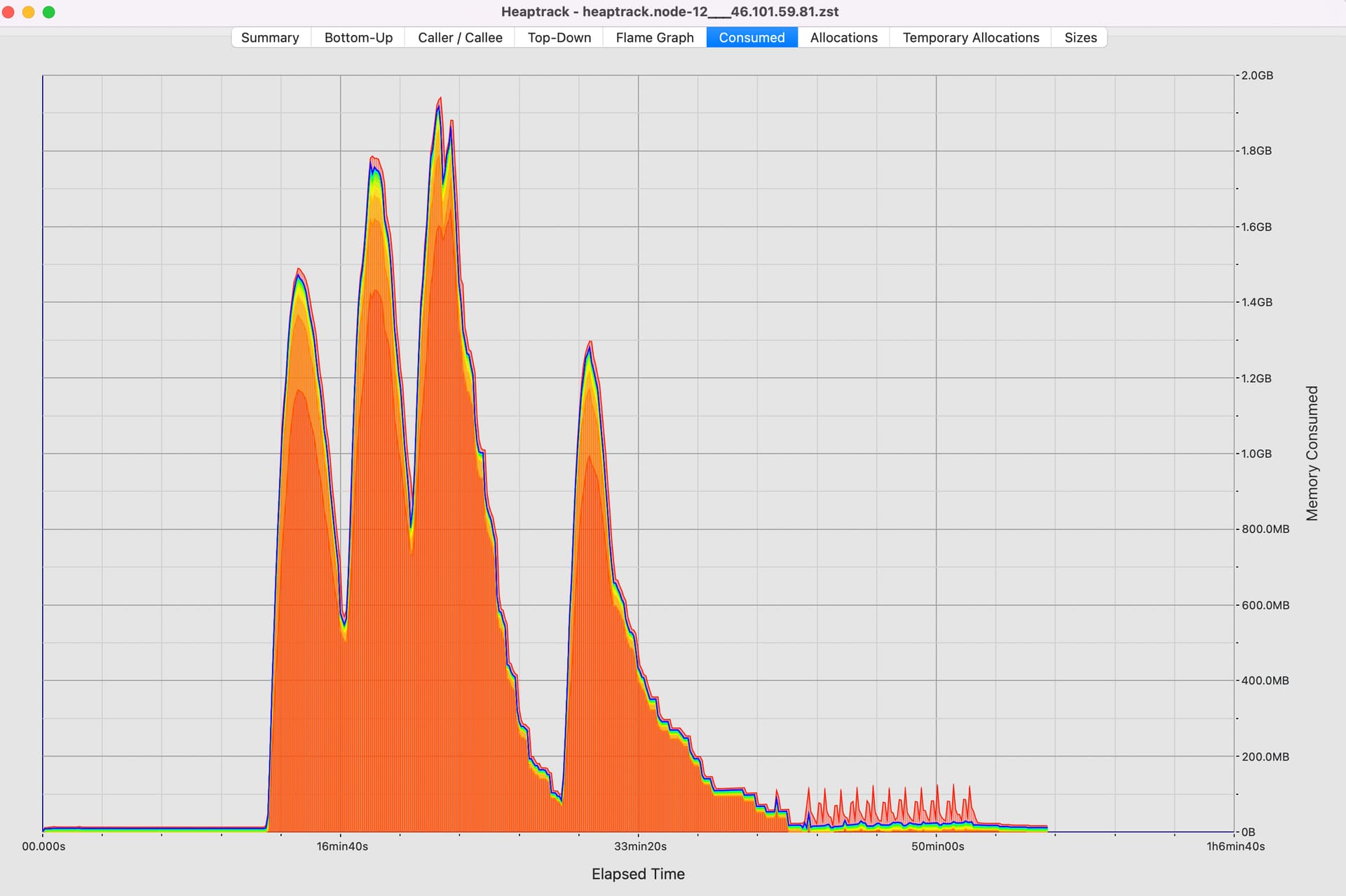
И това е за предстоящия PR:
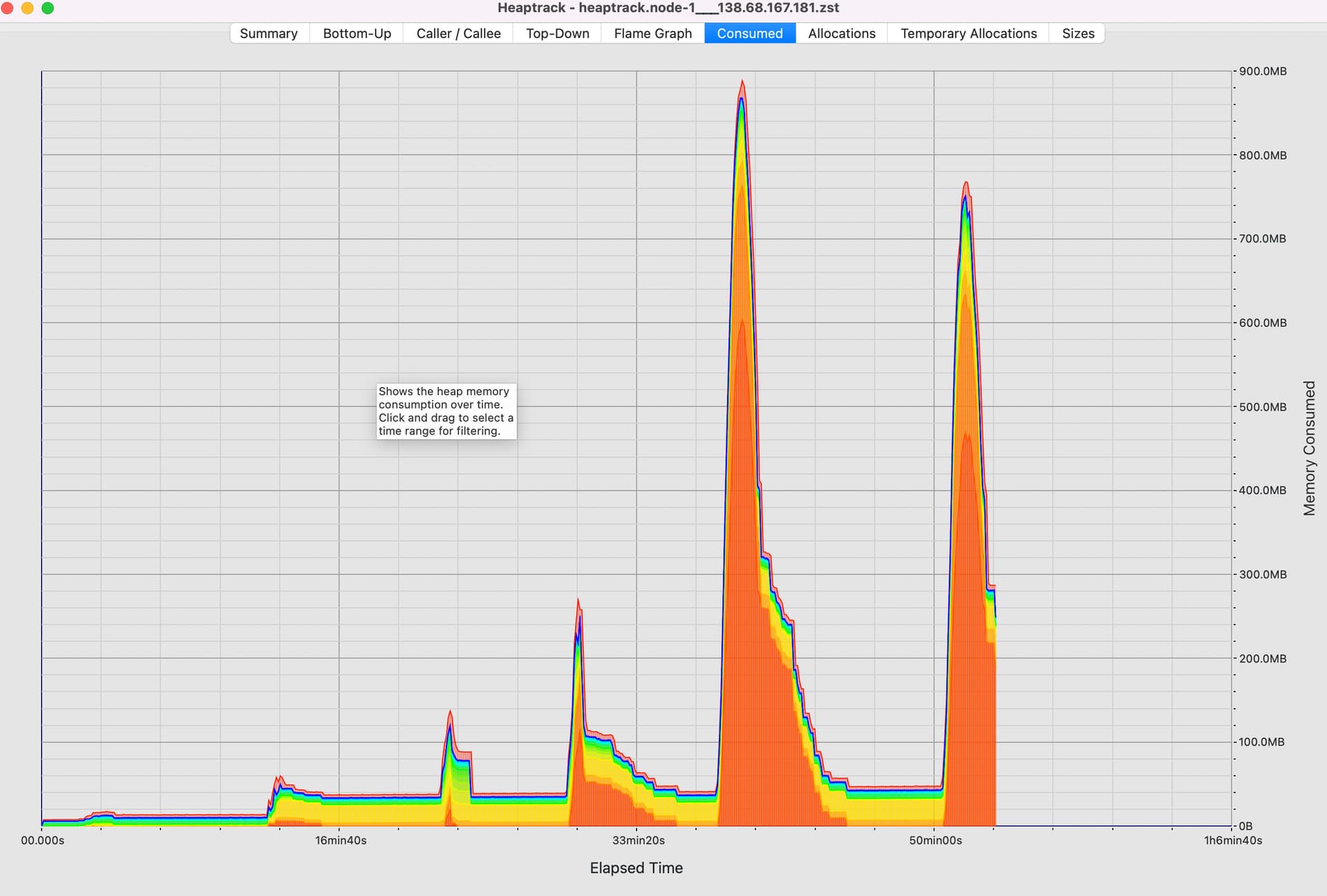
Можете да видите, че пиковете за тези тестове изглежда достигат по-бързо и с по-малко обща памет (~900MB срещу 1800MB). И с това нашият нов бенчмарк измерва пропускателната способност на изпращане на едно „WireMsg“ до 1000 различни „Dsts“.
- основна пропускателна способност: 7.5792 MiB/s
- PR пропускателна способност: 265.25 MiB/s
Което също е доста приятно.
Клонът все още не е обединен, трябва да се направи окончателно подреждане, преди да го включим, но изглежда като обещаваща промяна, която може да помогне на възлите да работят на по-икономичен хардуер (или се надяваме да позволи на @southside да качва повече в своите локални тестови мрежи!? ![]() )
)
Преводи:
![]() English
English ![]() Russian ;
Russian ; ![]() German ;
German ; ![]() Spanish ;
Spanish ; ![]() French
French
- Официален сайт на Safe Network
- Обобщено представяне на Safe Network
- Safe Network Фундаменти
- Карта на проекта
- Подробна информация може да намерите както винаги във форума на международната общност: Safe Network Forum
- Ако имате въпроси може да ги зададете във Facebook групата на българската Safe общност: Redirecting...
- Ако искате да следите последните новини заповядайте във Facebook страницата на Safe Network България: Safe Network България